まず役割サービスだと思いますが、[データ重複除去]を追加します。

(途中のウィザード画面は飛ばします)
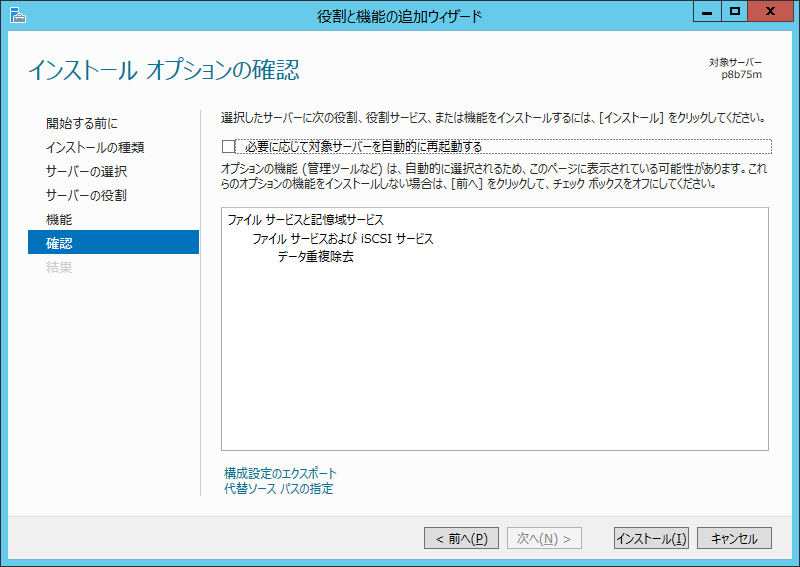

Dドライブの状態を見ておきます。111GBほど消費していますね。
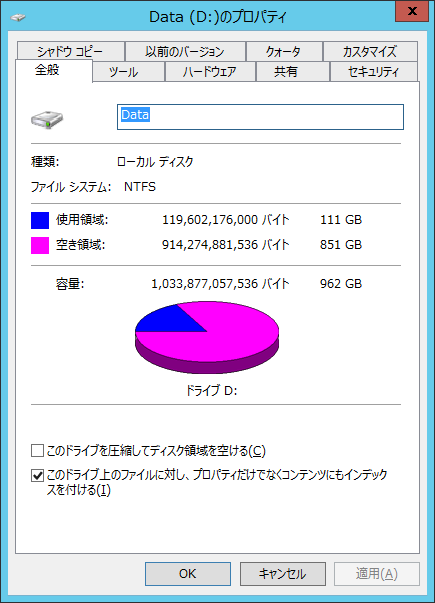
Dドライブに重複除去の設定を行います。VDIではありませんが、重複除去から除外する拡張子は、このまま都合良しと考えたので、これでいきます。
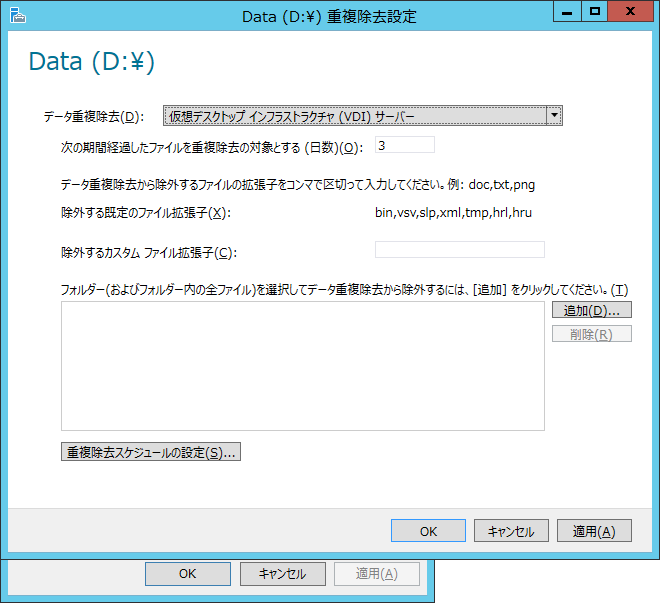
重複除去スケジュールはバックグラウンドのみとします。
すべてのVMを停止し、start-dedupjobコマンドレットで、データ重複除去を開始。

ジョブの状態は、get-dedupjobコマンドレットで確認できます。

30分ほどほおっておいたところ完了していたので、Dドライブの状態を見てみます。

なんと使用領域が20GB強にまで減少していました。
サーバーマネージャーでは削減率も確認できます。

実環境に使うのはためらわれるかもしれませんが、確かにデモ環境ならかなり良い感じですねぇ。
0 件のコメント:
コメントを投稿